
Conducting reproducible research with Docker (Part 1 of 3)
Published:
In scientific research, reproducibility is a necessary (though not sufficient) condition for validity. But conducting reproducible research is hard! Sadly, many psychological studies fail tests of empirical reproducibility. Unfortunately, there’s no software package that can solve the set of structural and statistical issues likely at the root of those non-replications.
Still, there are some tools that can help us achieve statistical or computational reproducibility. This kind of reproducibility means that another researcher can take our data and reproduce the analyses we conducted in a published paper. Sadly again, many studies in psychology fail here too. However, here the problem really might be solved with better tools–tools like R Markdown that can help ensure that our results sections are reflective of our actual analyses.
Here I’m going to describe another tool for producing statistically and computationally reproducible research, Docker. Reproducibility demands we make available the data and analyses scripts used in our research projects, but sometimes the line between our personal computer systems and our projects can start to blur. Our projects have “dependencies” that are required for them to run properly. So, to ensure other researchers can reproduce our projects, we need to clue them in to these dependencies in some way. The simplest way would be to dump our sessionInfo() at the bottom of the page. That’s easy in the moment, but not easy down the road for those who want to reproduce our work. The easier we can make reproducible research the whole way through, the better. Keep in mind, the researcher most likely to attempt to reproduce your work is future you.
Here, I’ll show you how to use Docker to create reproducible workflows for scientific research.
What is Docker?

Docker is a tool for making containerized applications. The docker engine is like a very lightweight virtual machine engine. A virtual machine is (to oversimplify) a computer program that simulates another computer system, typically another operating system. This allows you to run a windows app on your mac, or a linux progam on windows, and so forth.
Docker creates a “containerized” version of an application that includes everything needed to run the app: OS, headers, libraries, packages, etc. This container is saved as an “image”, that can then be shared with others. This allows people working on different computers, with different OS versions, package versions, etc to share and execute code or apps. So long as you have Docker installed on your computer and the right Docker image, you can spin up a container that will exactly reproduce the environment needed for the app, no matter what your own personal computing environment looks like.
Maybe you’re seeing how this can help us do reproducible research: if we create a containerized version of R, we can ensure we have R, R packages, system libraries, etc all in the right versions to reproduce the analyses. And because everything is held together in the container, if we share the image with another researcher, or with our future selves, it won’t matter that they might have a different computer with different OS, packages, etc.
The Rocker Project
Carl Boettiger and Dirk Eddelbuettel at The Rocker Project have done the hard work of properly organizing R and RStudio server applications into well-maintained and versioned Docker images. These Docker containers run R and RStudio server with sensible security options and some helpful base packages. Their website is also a good resource for help using these images. In this tutorial, we’ll use their image to run RStudio server in a Docker container. In Part 2, we’ll build off their work to make our own image with whatever packages we like.
Docker vs. Packrat
There’s another solution to the problem of statistical and computational reproducibility in R, called packrat. I will admit I don’t have a great deal of familiarity with packrat, but I can discuss some differences. First, packrat is focused on R and R alone. This means if you incorporate other languages (e.g., python) in your projects, you will need multiple reproducibility solutions. In contrast, Docker handles everything. Second, Docker gives us other nice and powerful features, such as an easy way to run code remotely on cloud servers. Finally, there’s nothing stopping you from using both approaches (even using packrat inside your Docker container).
Tutorial
In this tutorial we’ll …
- Install docker
- Make a docker cloud account
- Run a docker image from docker cloud
Along the way, I’ll assume you are comfortable using the terminal. I’ll also assume you’re on a mac, though things shouldn’t be that different on Linux. I can’t really speak to Windows, but the overall process should be similar.
1. Installing Docker (on Mac)
I’d advocate for installing Docker on Mac using homebrew. If you don’t have homebrew, Docker has an installation guide for mac that covers all the steps to install the traditional way.
To install using homebrew, open up terminal and run:
brew update && brew cask install docker
Then launch docker from your applications (or with spotlight, cmd-space and type “docker”). You’ll need to enter your administrator password.
Optional: set up bash completion for docker by running the below commands in terminal:
brew install bash-completion
brew install docker-completion
brew install docker-compose-completion
brew install docker-machine-completion
2. Make your Docker cloud account
When you first launch Docker it should prompt you to sign in or create a Docker cloud account. Alternately, you can go to hub.docker.com and create an account there. Dockerhub is a centralized store for docker images (saved containers). In the next step, we’ll grab an image from dockerhub to run a container our machine. Eventually, this will host your own personalized docker images (part 2 of this series).
In the next step, we’ll load the tidyverse container from the rocker project’s page on dockerhub.
3. Run a docker image from docker hub
Ok, now let’s actually get a docker container image running on our machine. First, make sure Docker is running on your machine (check the menubar for the icon). Then, head back over to terminal and enter the following command:
docker run -d -p 8787:8787 -v "`pwd`":/home/rstudio/working -e PASSWORD=rstudio -e ROOT=TRUE rocker/tidyverse:3.4.3
There’s a lot going on in here so let’s break down this command.
- The first part,
docker runsays we want to start running a docker container. - The
-dflag tells the container to run in the background (detached) - The
-p 8787:8787flag maps port from inside the docker container to the main computer. This container will end up running an instance of RStudio server, which will be available atlocalhost:8787. Port 8787 happens to be the default, but it can be nice to be explicit. - The
-v `pwd`:/home/rstudio/workingflag uses the –volume tag to connect the filesystem on our machine to our docker container. It maps our present working directory to a folder in the docker container called “working” that’s in a location we can access through the RStudio interface. This lets you access whatever data or project files you need from your computer in the docker container. - The
-e PASSWORD=rstudioflag sets an environment variable “PASSWORD” to “rstudio”. This sets the password to access the rstudio server instance. Here we’re just explicitly setting the password to the default, “rstudio”. If you run this remotely (part 3 teaser!), this should obviously be changed. - The
-e ROOT=TRUEflag gives us root access from inside RStudio. This can be helpful for installing linux dependencies when installing R packages. - Finally
rocker/tidyverse:3.4.3specifies the docker image to run. That is, version 3.4.3 of the rocker/tidyverse image. If we didn’t specify a tag, docker would default to the “latest” tag.
When you run a container without its image present locally, Docker will automatically download it.
Using RStudio
Now open up your browser and navigate to localhost:8787. Enter “rstudio” as your username and whatever password you set as the password (defaults to “rstudio”).
You will then be met with a fully-functioning RStudio interface. In the lower right you should see the file browser with the “working” directory we mapped when we ran the container.
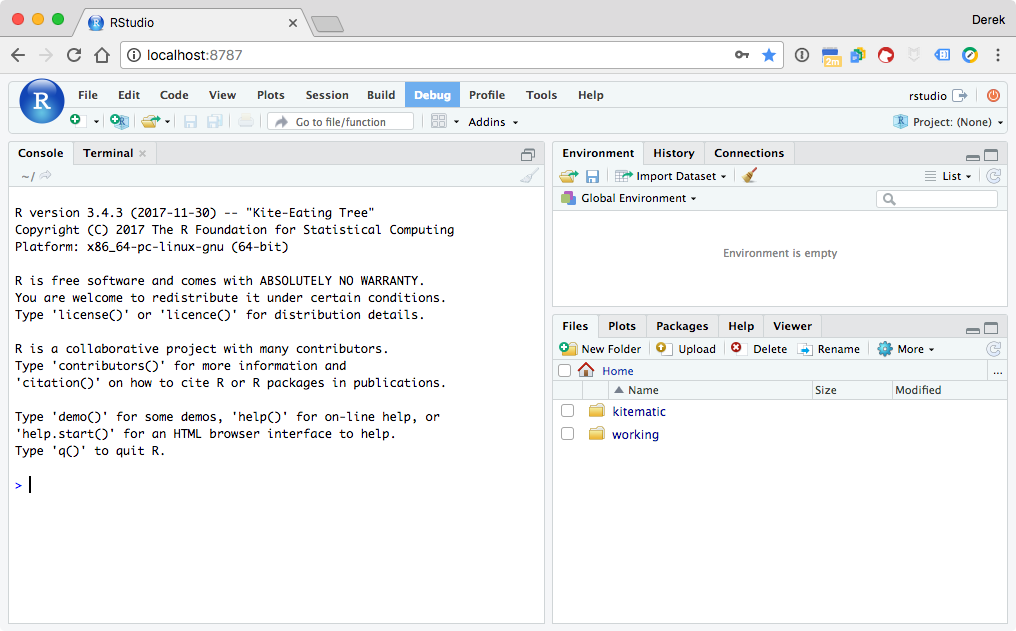
If you make changes to files in “working” inside this Docker container, they will also be reflected on your computer’s file system.
Feel free to play around with this, you can see the already-installed R packages by typing sessionInfo().
Configuring your container
Finally, you may need to adjust how much of your machine you allow Docker to use. On mac, Docker is very “polite” so it doesn’t give itself very much of your machine’s resources. But, because you plan to be working in this container, you will probably want to give it some more juice.
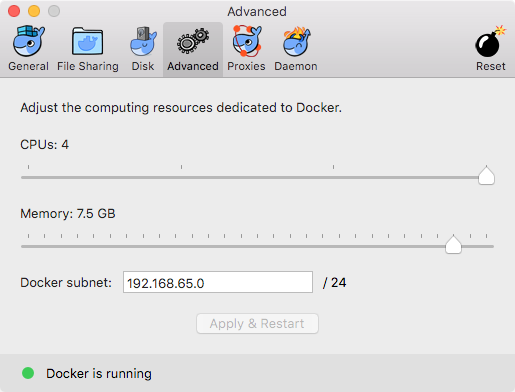
To fix this, access the docker preferences via the menu button and select the “advanced” tab. Then, adjust to your liking. There doesn’t seem to be any harm to letting docker have full access to your system resources, at least not when used in this fashion.
Coming up next …
That’s it for Part 1 of this series. Next, in Part 2 we’ll discuss customizing a docker image with your own personal R environment. Till then you might want to poke around a bit and see what’s available on dockerhub. I won’t cover it’s use in this series, but if you do any work in python, the jupyter notebook datascience container is worth checking out.